
PyYorch深度学习入门
安装
pytorch的安装
面对不同的工作环境,对于pytorch的版本要求可能不同,而不能同时安装两个环境,因此就需要Anaconda集成的conda包解决这个问题,它可以创造出两个屋子,分别存放不同的版本
conda create -n pytorch python=3.6

(安装完成),这里由于个人是AMD显卡,因此仅安装了cpu版本,对于学习来说应当已近是足够的
关于jupter的安装
jupyter是直接安装在base环境中的,可以用conda list指令看到base环境中是有一系列“i”开头的文件包的,而在jupyter环境中是没有的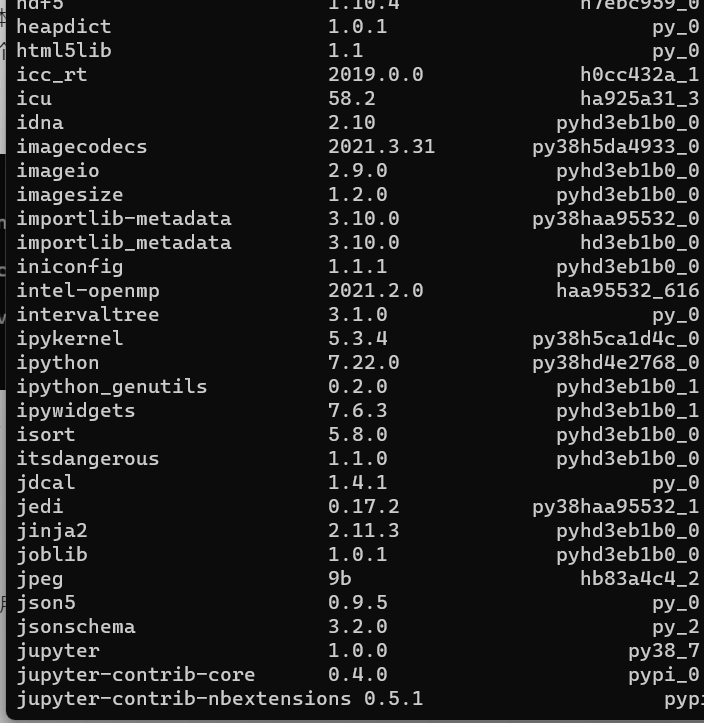
此时,我们需要使用conda install nb_conda便可以将Jupyter安装在pytorch环境中了
安装完成后,输入jupter notebook即可打开jupyter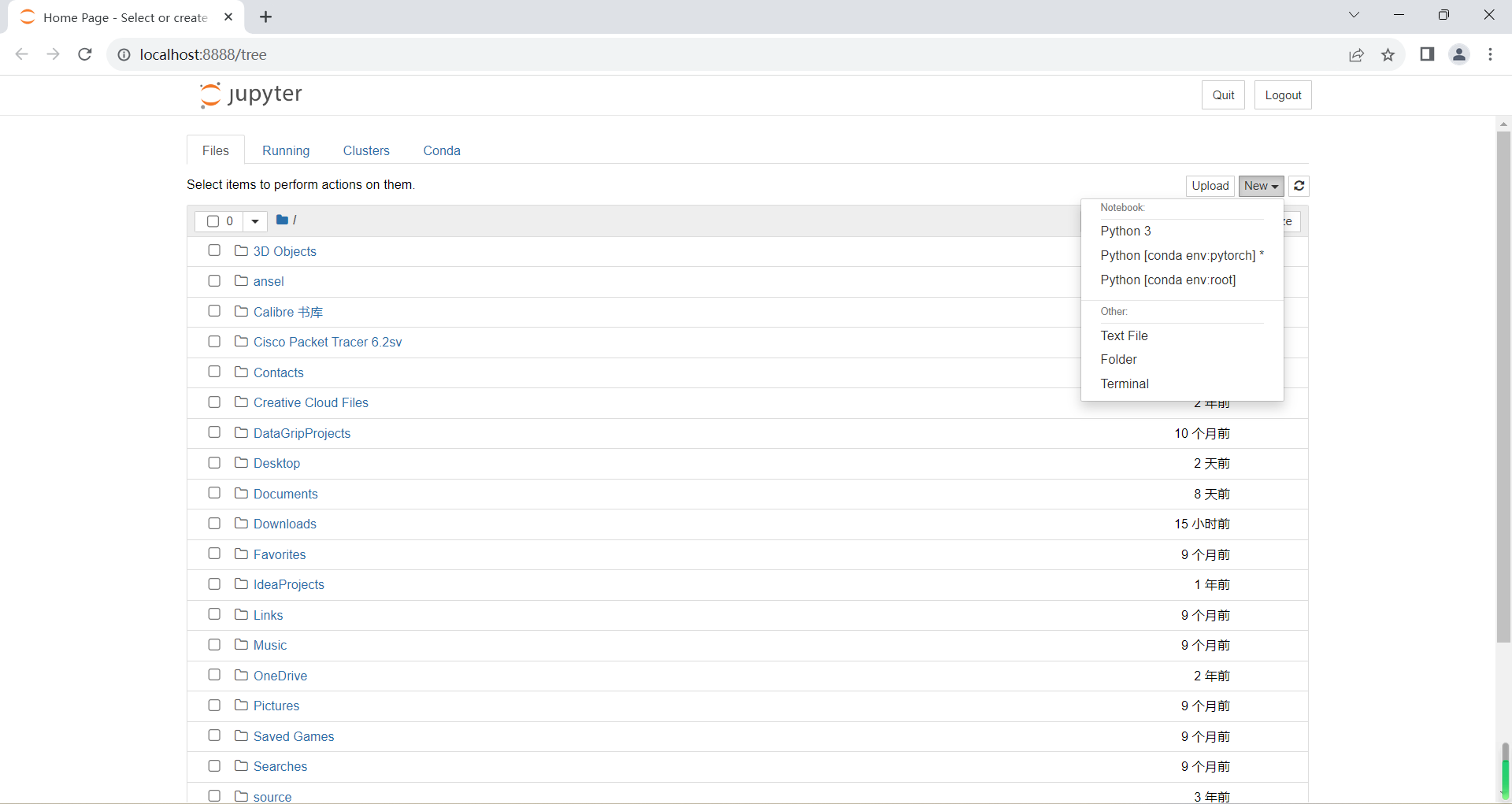
右上角选择new,我们是conda版本pytorch,在此创建代码即可
Dataset类的实例
前置的两个帮手函数:
1、dir()获得文件包
2、help()获得指定函数的作用
实例的数据集:蚂蚁蜜蜂/练手数据集:
链接: https://pan.baidu.com/s/1jZoTmoFzaTLWh4lKBHVbEA 密码: 5suq
process
导入pytorch的常用包和图像处理的包之后,这里用控制台可以清晰看到每步走的流程
首先设置一个路径,方便起见,将数据包直接移到了项目文件夹中,在pycharm页面,直接copy路径即可,我此处使用的是相对路劲,因为使用绝对路径换一台电脑可能就使用不了了。随后将这张图片由地址赋给一个变量,使用show函数即可获得图片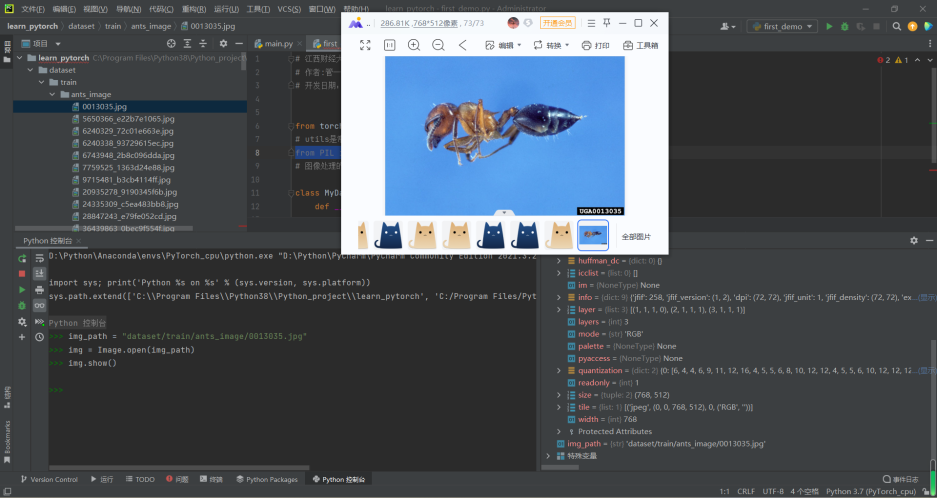
以上是直接获得一张图片的情况,如果想要获得一组图片,则需要导入系统包os。下图操作分别为设置一个root_dir,这里设置为train数据集的相对地址。label_dir则为自己对这个文件夹下分类的定义。随后用path变量保存拼接后的地址,使用os.path.join()函数将一个地址和地址下的子文件夹拼接起来。最后用image_path保存由地址转为图像后的列表,使用方法为os.listdir()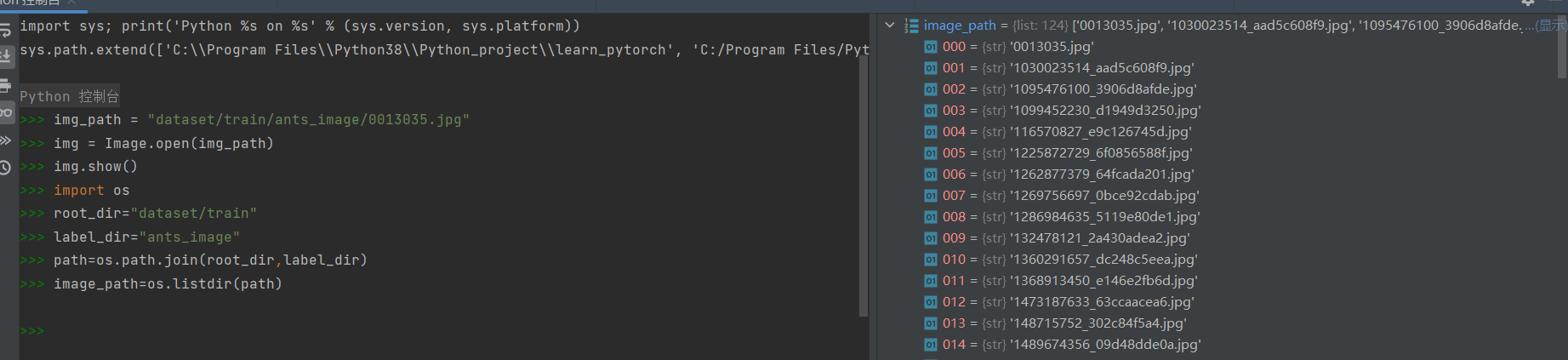
获得一张图片的系列信息
获得一组数据的长度
这里通过初始化获得了蚂蚁数据集和蜜蜂数据集,将他们相加混合在一起放入train_dataset中,直接调用len函数获得列表长度即可获得整个数据集的长度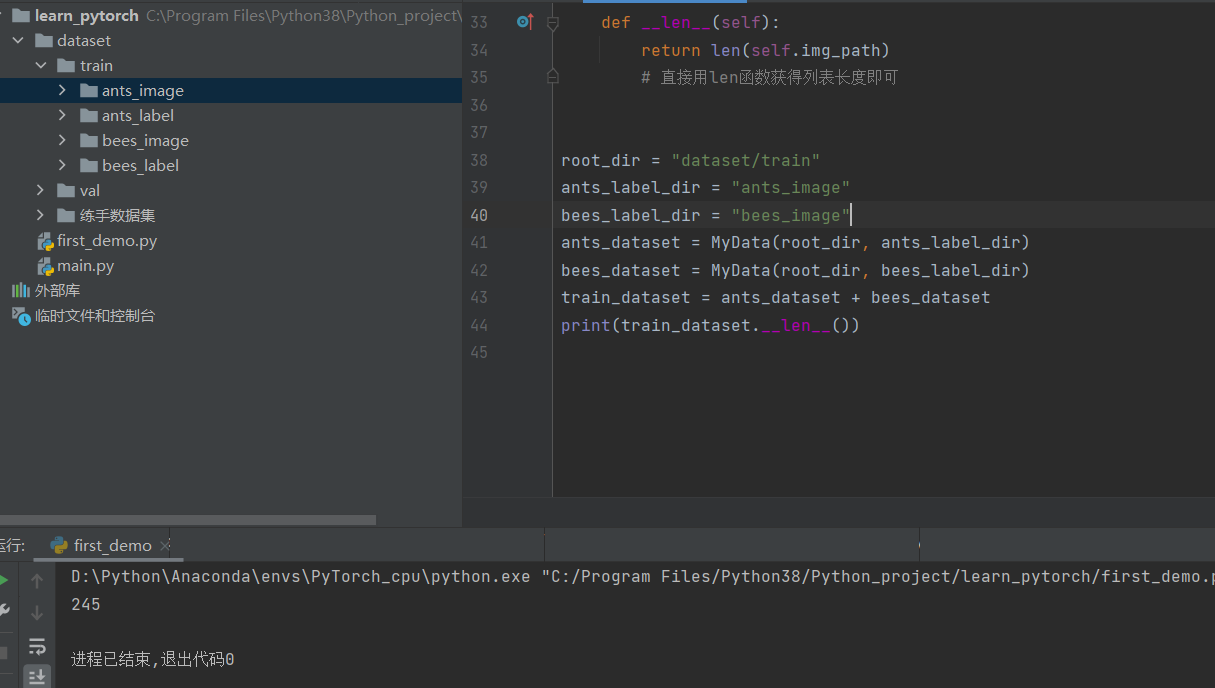
完整代码
1 | from torch.utils.data import Dataset |
Tensorboard
在pytorch环境使用pip install tensorboard命令安装tensorboard(注意,这里如果网速不好会pip失败,建议手机热点或者尾巴加上国内镜像链接)
出现这个界面即为安装成功
输出y=x函数图像的代码
1 | from torch.utils.tensorboard import SummaryWriter |
出现的问题
1、在pycharm中terminal没有pytorch环境
解决方案:设置中将终端中的Shell Path改为C:\Windows\system32\cmd.exe
2、运行文件时提示没有six包(这个是导入Summary Writer产生的问题)
解决方案:直接import six
最后可以看到文件夹一块会多出一个“logs”文件夹,下面是tensorboard的一些事件文件
如何打开这个文件?
在terminal窗口输入tensorboard –logdir=logs (后面跟的logs就是指定文件夹),注如果很多人使用的话,可以在末尾加上指定以防冲突,如–port=6007
点击下方的端口就可以看到绘制的图像了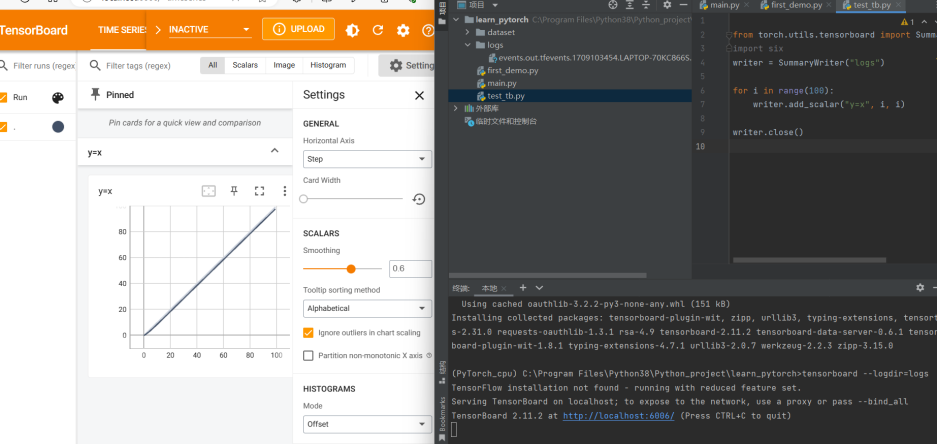
注意:logs会记录所有writer添加的图像,如我先做了y=x,再做了y=2x,那么现在的图像就会是二者的拟合。而解决这个问题只需要将logs文件夹下的文件删除重新运行即可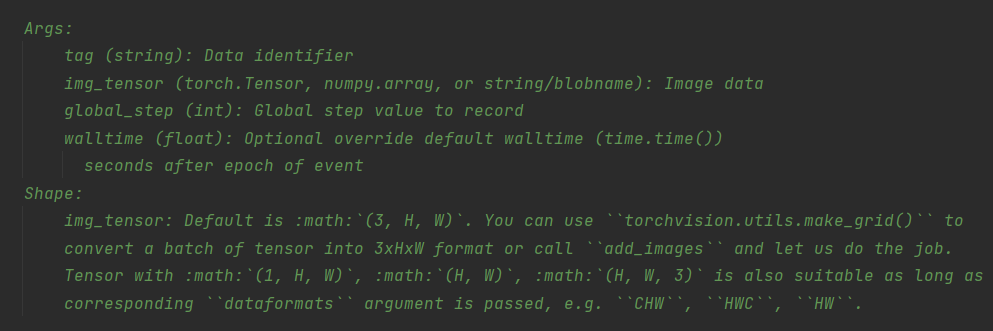
通过writer.add_image函数将图像添加至步骤中更直观的运行
实现代码:
1 | import numpy as np |
实现结果
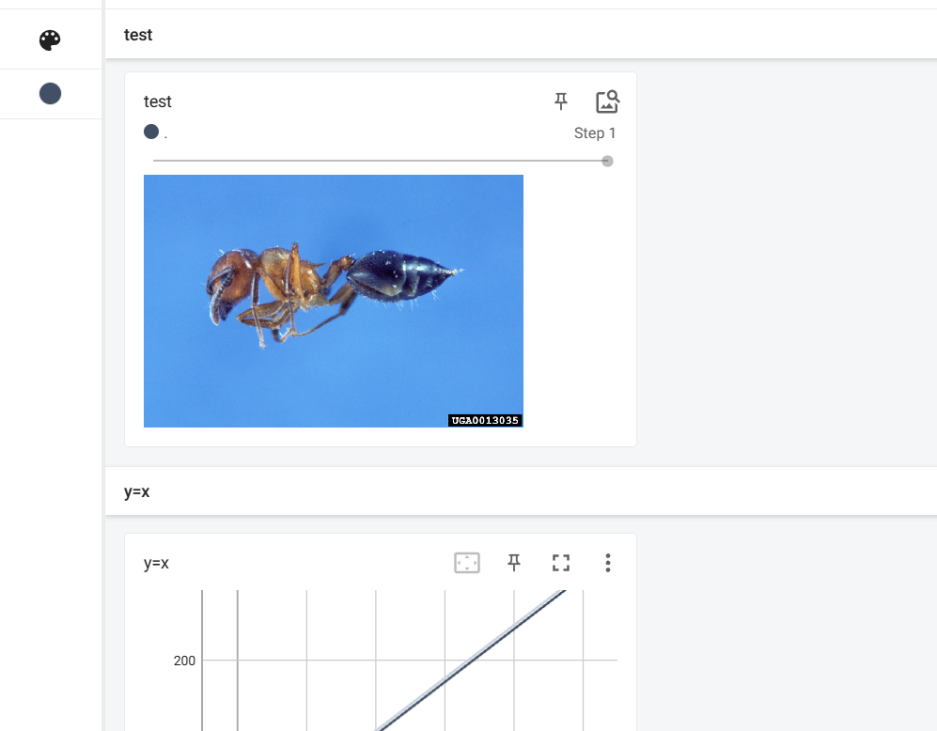
注意,add_image函数的对象只能是特定类型,并且图像的格式必须要按照要求,详细如下,可参照维度所在的位置调整
