
机器学习基本原理
生成式AI
机器学习的定义
机器学习:机器自动找一个函数
1、在chatgpt中,函数就是根据输入预测下一个要输出的字,这个字在英文中即为token,是介于字母和单词之间的,如unbreakable分为un、break、able,最后组成一组回答
2、在midjourney中,函数就是根据输入输出一张符合的图片
3、在ALphaGo中,函数就是根据输入的棋盘,输出下一个要下子的位置
根据函数输出来分类
1、回归(regression):函数的输出是一个数值
以宝可梦举例
1)input为宝可梦初级的cp值(combat power,战斗能力),输出为进化之后的战斗能力。公式为常数值b加权重×input,即b+w乘cp。用大量数据集去调整b和w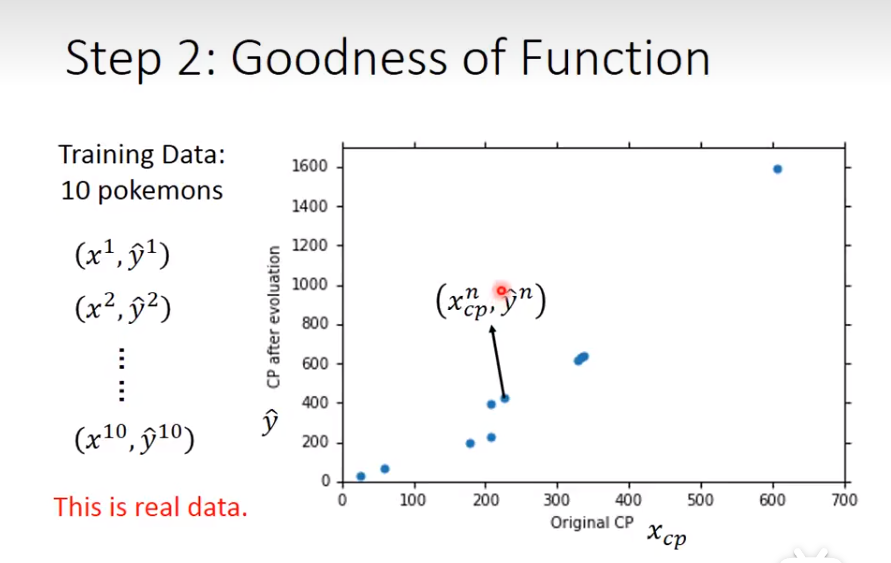
2)定义一个function的好坏,lossfunction
input为一个function,output为这个functionu有多不好
(结果:蓝色说明结果越好,红色误差越大)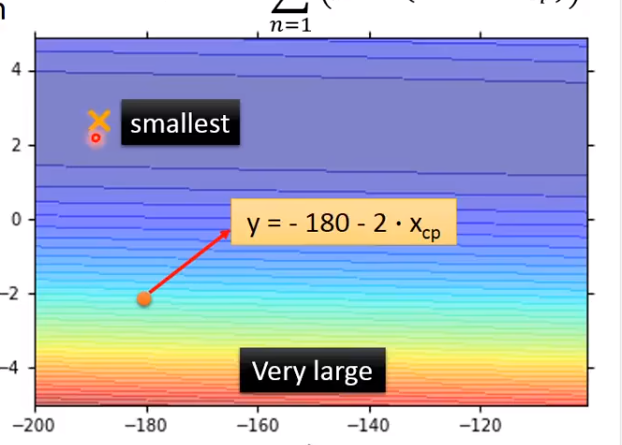
3)挑选一个最好的function
(第一个为输入f,找到最小的f。第二个为穷举所有的w和b,得到L最小的w和b,最后一行只是这个L的一种常用方法)
4)Gradient Decent(梯度下降)
随机找一个点,也可以通过某种方法找到一个比较好的点,计算这一个点的微分,如果是负的,则需要增加w(就是看斜率,让loss最小)。往右踏的步数叫做η,也叫作learning rate,右移以η×斜率。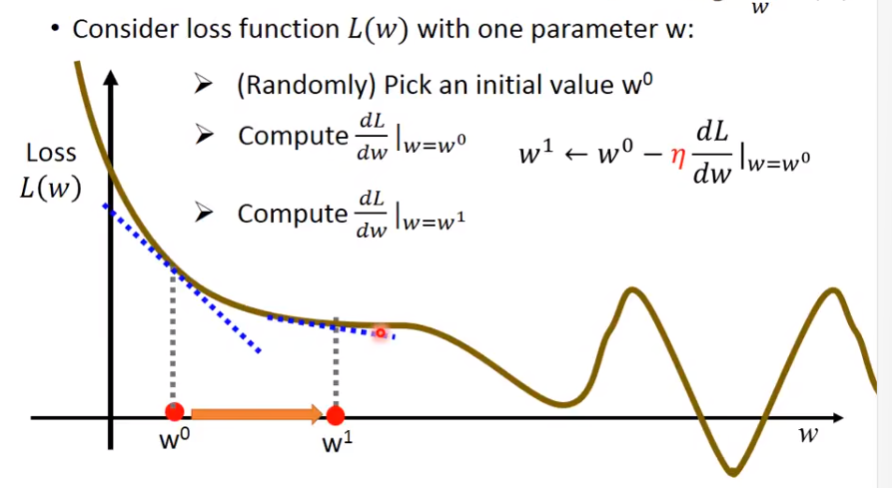
二维情况,走的方向为法线方向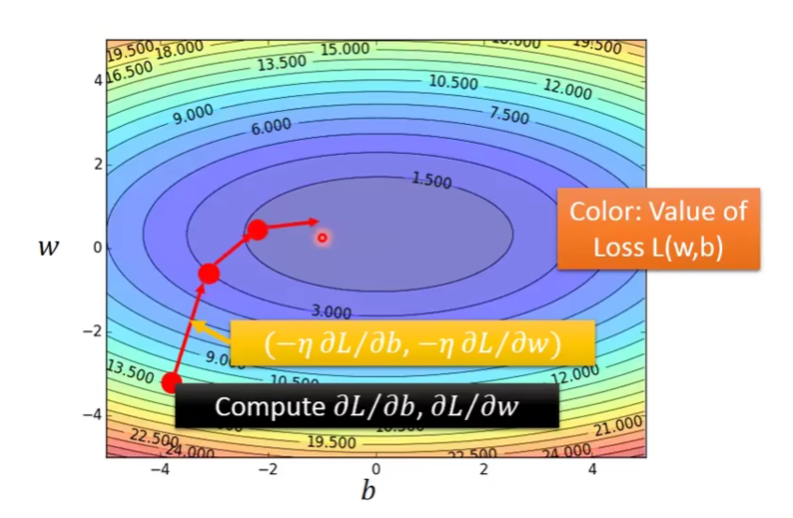
过拟合:越复杂的模型在训练数据上有一个非常好的结果,测试数据上并没有一个更好的结果。在训练数据上有一个好的结果的原因是例如模型为b+w1×x,更加复杂的模型为b+w1×x+w2×x²,复杂模型已经包含了简单模型,所以在训练数据上会有一个更好的结果。
正则化(regularzation):如果发生过拟合问题,那么原因可能是例如,x立方的系数c或者x四次方的系数d过大。而通过正则化,将误差不仅考虑(实际值减去计算值)而且考虑这里的c和d,使得方程更加线性化。L1就是多考虑的用绝对值,L2就是多考虑的用平方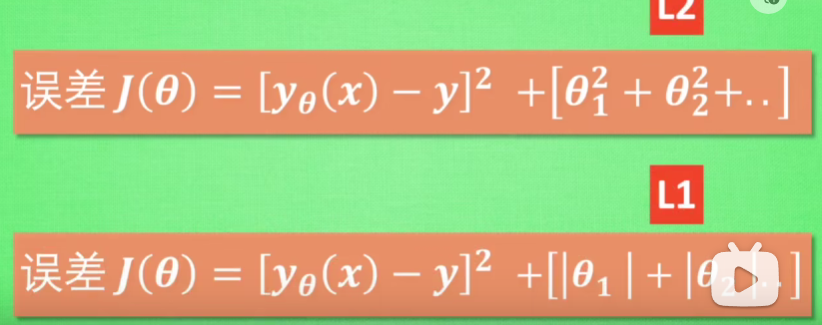
一个比较好的正则化讲解视频
2、分类(classification):函数的输出是一个类别(选择题)
用作方向:例如在保险行业,输入为年龄职业等,输出为是否要借钱给他
那么,再次跟着大木博士学习宝可梦知识,如果在战斗中,根据数值即可知道对手宝可梦的属性,在属性克制上就会有非常大的优势。我们可以用攻击、防御、血量等等数值组成一只宝可梦
是否能用regression来解决这个问题?
可以假设,当输出值越接近-1,则属于class1;越接近1,则属于class2,我们肉眼可见在左侧图中,绿线能够很好的分割,同时也能找到这样一个权重。可如果当有一些远远大于1的数据,如在右侧图中,有一些error数据,数值就会产生偏差,因此并不能很好的解决属性分类这个问题。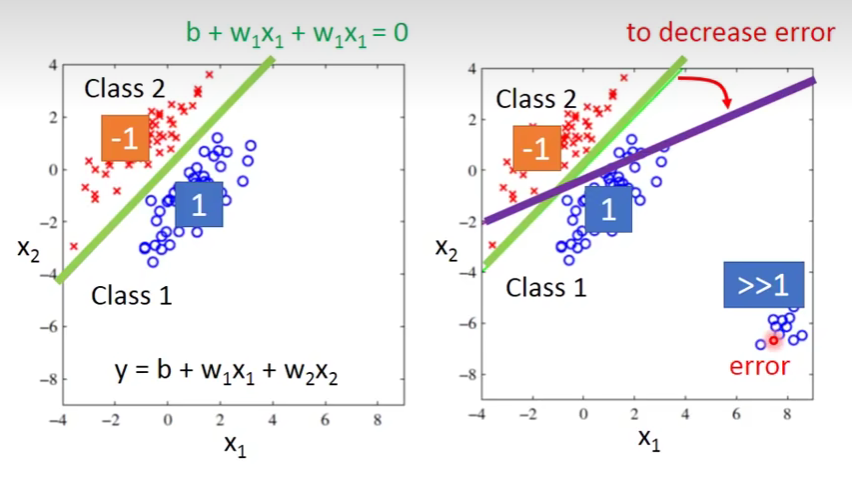
分类和聚类的区别:分类的分类数量是已知的,例如在一张图像上对已知的动物做分类。而聚类是交给机器去做的,聚类数量是未知的。分类是有监督的,人为分类和定义每一个类别是什么,而聚类是无监督,把整个聚类过程都交给机器。
找出函数的三步骤
1、设定范围,找到函数的集合,有多少种合适的函数
当训练资料少的时候,化的函数就会非常多,就需要保守一些,化的范围小一些
当训练资料多的时候,化的函数就会更少,可以化多一些范围
2、设定标准,定出评价函数好坏的标准,这个函数叫做loss function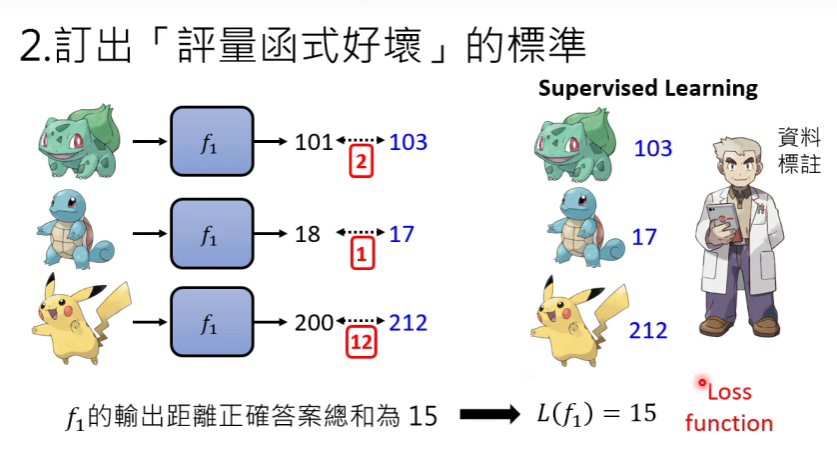
3、找出最好的函数,即损失函数最小
生成式学习的两种策略
生成式AI中,对于生成的结果有两种生成方法,即各个击破和一次到位。各个击破是指通过预测下一个文字的输出概率来一个个生成,需要的时间比较长,但是品质比较高,常用于文字。而一次到位生成的品质会比较低,但是速度非常快,由于影像的像素太多了,所以常用一次到位
能否将二者结合呢?
首先在影像中,我们可以将一次到位改变为N此到位,如一只猫的影像,可以先生成一张一张大致的轮廓,再不断合成,产生一张更加符合的影像。或者在声音合成中,可以将一段文字,先用各个击破的方法生成中间产物,如每秒100个向量,再通过一次到位生成16K取样频率的声音
大模型
人类对两种语言模型的期待
1、成为专才,专注于做一件事情,例如BERT(google训练的文字填空的模型)。BERT相较于GPT系列有一个非常大的劣势就是不会讲话,因此需要给他加上模组才能让他做想做的任务,同时需要对模组进行微调(Gradient descent)
2、成为通才,对于任何的语言输入都能做一个合理的回答。
In-context Learning案例分析
In-context Learning即从类比中学习的方法,通过连接示例和输出来进行预测
在案例分析中,给的案例是否能对机器起到学习作用?在Rethinking the Role of Demonstrations:What Makes In-Context Learning Work这篇论文中有介绍到,这些语言模型本身就会做情感分析,只是给的例子告诉了他此时需要做情感分析任务,启动了机器而已。 因为论文中的测试写到,如果给机器错误的范例,机器的正确率相比于给正确的案例并没有下降很多,甚至还是比没有给案例高出些许。而当给出不相关的例子的时候,机器的正确率则会明显下降,由此可以大致猜测例子可能只是作用于唤醒机器。在下图中可以发现,当案例数增加的时候,很快就收敛了,它并不是透过这些例子来学习,只是唤醒这些记忆,所以给多了例子作用并不大。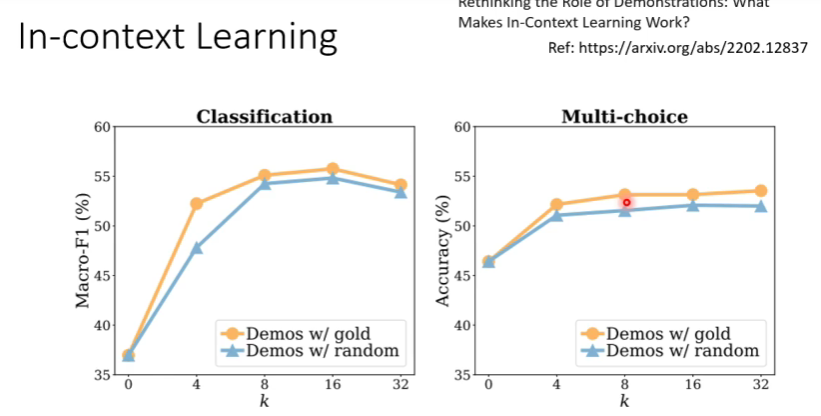
大模型的顿悟时刻
1、当数据量大到一个程度的时候,模型会突然顿悟。不断加大数据量的时候效果却并不是很明显,这就会使得在说服投资人上面产生问题。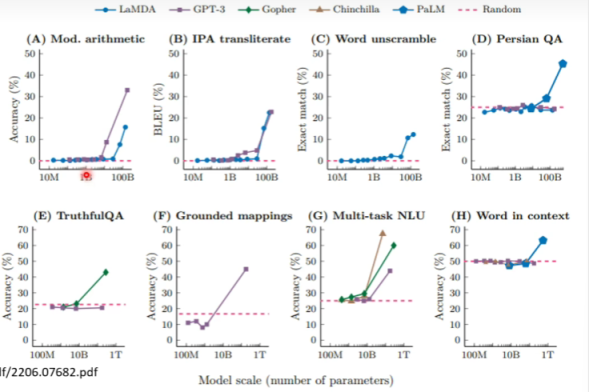
2、当模型回答了一个看起来很无厘头的问题,并且给出错误的答案时,模型是否知道自己在瞎扯?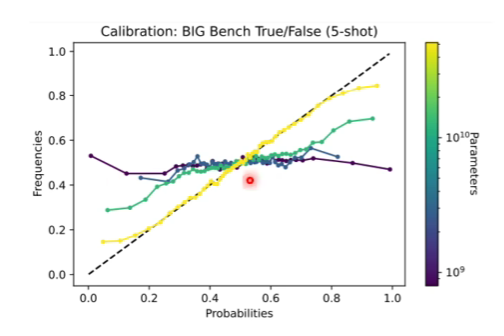
其实当模型在回答这个问题,预测下一个字输出的可能性时就可以看出,如果他认为出现一个字的可能性很高,那么很有可能他是知道答案的,而如果他认为出现一个字的概率很低,可能他已经知道自己在瞎掰了。由上图可知,随着模型越来越来,模型对自己的认知是更加清楚的,而对于小模型,模型可能并不知道自己在瞎掰。知道自己是否知道的答案的能力叫做Calibration(校准),而只有模型够大的时候才有这个能力。
3、为什么随着数据量的上升,模型的能力有时候会出现U型曲线?
随着数据量上升,模型逐渐从小模型-中模型-大模型,但是问的问题中可能会存在一些陷阱问题。如如果提问是π=10,π+1等于多少?对于中模型来说,它的认知就是π等于3.14,他可能会将它认知的标准答案直接加上去,因此会出现模型大了,反而能力削弱的问题,这也叫做“一知半解吃大亏”,而大模型就能很清楚的认知到题干想要做的事情
4、同样算力下,小模型、大资料还是大模型、小资料表现好?
明显可以看见,只有4个任务是大模型小资料胜利,小模型大资料表现更为突出。当然,这里的小模型可能对于我们来说也是非常大的。事实是,模型已经够大了,在我们的算力还没有跟上之前,我们应该喂给他更多的训练资料。
Instruction-Tunning可以让模型以非常小的代价做到提升,即对提问题进行训练,让模型知道自己要干什么,什么时候应该回答问题,这也是OpenAI成功的关键
5、怎么训练资料?
1、预处理,去除有害内容,这并不是用关键字,而是用Google的安全搜寻
2、去掉HTML的tag,但是也会保留换行空格等
3、用自己设定的规则去除低品质的资料
4、去除重复的资料(这个很有帮助哦),机器很容易说出资料里面经常出现的话,因此做一些清理之后,可以降低很多机器硬背的比例
5、测试,注意这里需要在不同的资料上测试,GPT3就犯过在相同资料上测试而出现的问题
KNN LM
1、一个一般的语言模型是如何运作的?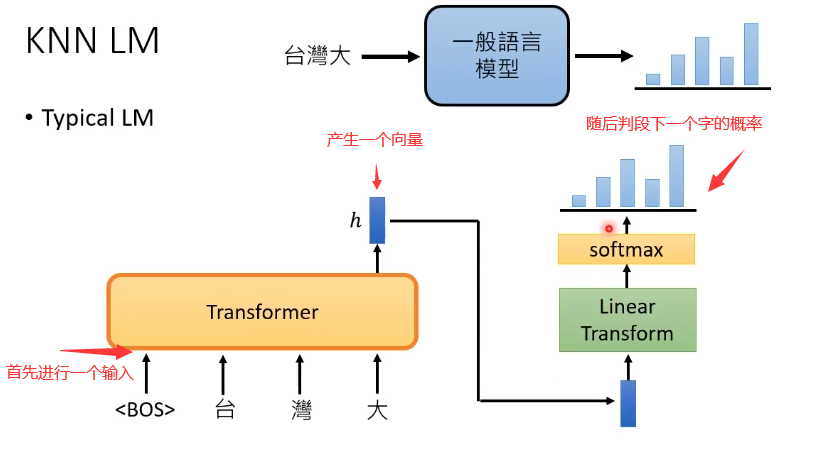
相比于一般的语言模型,KNN LM保留了输入后输出向量的过程。分析过程见下图,在多个训练资料中获得输出向量,找到相近的答案,再把这个答案计算出现的概率,最后将重复的出现答案相加起来,就可以获得最终的结果,这个过程是比较类似于搜索引擎的。KNN LM有个非常好的地方是,它并不需要特地的去记一个比较偏的词汇,只需要根据训练资料做结合即可,此外训练资料并不一定要去重,只要有足够的运算资源,可以把所有找得到的资料都丢进去。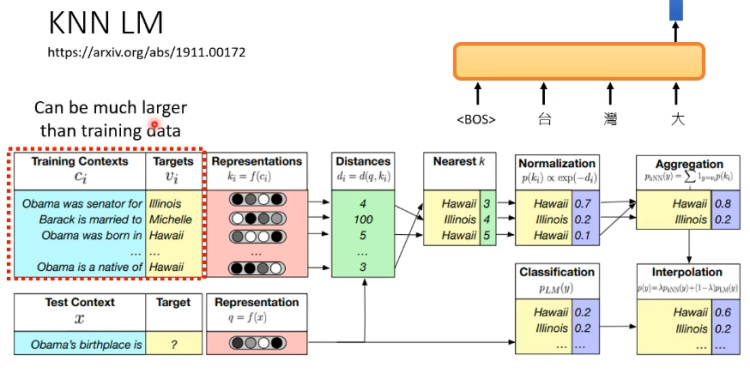
2、KNN LM的结果
蓝线是喂给KNN LM资料的大小,Perpiexity的变化过程。Perpiexity与文字接龙中预测下一个字的概率的准确率呈相反关系,换句话说Perpiexity越小,模型表现越好。左图可知,尽管没有很大的训练模型,当喂给KNN LM的资料越多(上图的Nearest过程),模型的表现是可以超过WIKI大模型的
3、为什么在chatgpt中没有用KNN LM?
太花时间了,一般语言模型虽然Perpiexity比KNN LM高,但是效率却比KNN LM高很多
